

Réplication avec mysql et Répartition de charge avec haproxy
Réplication en temps réel Master/Slave MySQL
- Présentation
L'importance des serveurs de base de données et des bases de données elles même dans un système d'information est capital à son bon fonctionnement tant au niveau applicatif qu'au niveau des lectures par les serveurs web. C'est pourquoi il est important, dans une optique de sécurité et de disponibilité de l'information, d'avoir un processus à la fois de réplication des informations en temps réel mais aussi de tolérance de panne. Plus précisément, si un serveur dit "Master" tombe, un autre serveur "Slave" doit prendre le relais de manière immédiate et doit aussi avoir la dernière version des informations.
Dans ce tutoriel, nous allons apprendre à mettre en place une réplication des bases de données en temps réel entre un serveur dit "Master" qui va recevoir les processus d'écriture et de lecture et un serveur "Slave" qui se chargera de se mettre à jour selon les modifications faites sur le "Master" afin qu'il dispose des dernières versions des informations et qu'il soit ainsi prêt à prendre le relais en cas de défaillance du serveur principal.
N.B : Il est important de savoir que plusieurs "Slave" peuvent être en place et peuvent pointer sur un "Master" afin d'avoir plusieurs niveau de "Fail-over".
- Explication du principe de réplication en temps réel
Avant de mettre en place un tel processus, il est important de comprendre comment il fonctionne. On part du principe que le serveur MySQL "Master" et le serveur MySQL "Slave" démarrent avec exactement la même base de données qui seront identiques. Quand une réplication est active et que le serveur MySQL "Master" connait son rôle, il va écrire toutes les requêtes modifiant son contenu ("UPDATE", "DELETE", "INSERT INTO", ...) dans un fichier tiers binaire qu'il aura créé lors de son démarrage, dans un second temps il enverra à son où ses "Slave" un événement de réplication que le "Slave" stockera dans son fichier binaire appelé "mysql-relay-bin". De son coté, le serveur MySQL "Slave" qui aura dans ses paramètres l'adresse, le port, les identifiants ainsi que des informations sur le fichier binaire en question ira lire ce fichier en local et effectuera en temps réel les mêmes commandes sur sa propre base de données.
Il est important de savoir que l'on peut choisir de synchroniser une, plusieurs ou toutes les bases de données d'un serveur MySQL. Le nom de ces bases doit être mis dans la configuration, ce que nous verrons un peu plus tard. Il est aussi à savoir que les processus d'écritures ne doivent se faire uniquement sur le serveur MySQL Master. Si l'on commence à écrire sur le "Slave" et que le "Master" ne contient pas cette modification, la synchronisation et la réplication seront faussées. Voici un schéma expliquant brièvement ce processus :
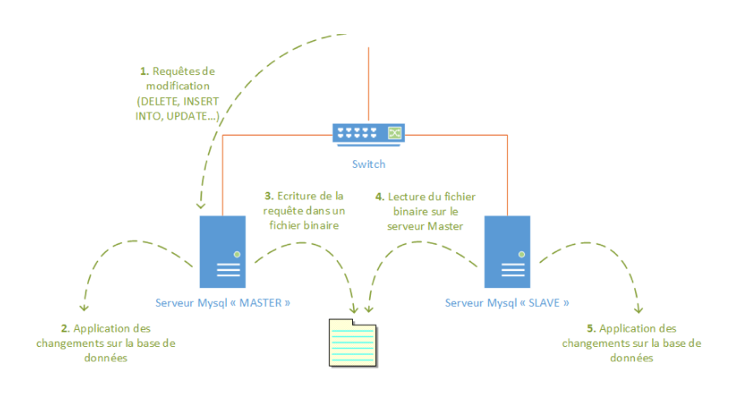
III. Mise en place de l'architecture
N.B : Cette partie explique la mise en place basique de l'architecture, des serveurs MySQL, d'une base de données "test" et des accès nécessaires à la réplication. Passez directement à la partie "IV. Configuration du master" si vos serveurs, bases de données et accès sont déjà en place.

Notre serveur MySQL "Master" aura l'IP 192.168.1.110 et notre serveur MySQL "Slave" aura l'IP 192.168.1.113. Les écritures depuis les serveurs web ou toute autres applications se feront donc directement sur le "Master" et jamais sur le "Slave" (hormis si le "Master" est défaillant, ce que nous verrons plus tard). Nous allons sur nos deux serveurs installer MySQL;
# On met à jours nos paquets
apt-get update
# On installe le serveur MySQL
apt-get install mysql-server
Pour que notre serveur "Slave" puisse recevoir les événements de réplication envoyés par le serveur "Master" par un processus expliqué plus tard, nous devons ouvrir notre serveur MySQL à l'écoute sur l'extérieur puis créer un utilisateur qui aura les droits de réplication et de lecture sur les bases voulues :
# Sur le Mastervim /etc/mysql/my.cnf
bind-address = 0.0.0.0 // ou préciser l’adresse du slave 192.168.1.113

On met à l'option "bind-address" qui sera l'adresse d'écoute du service MySQL l'adresse IP du serveur "Master" pour qu'il se mette à écouter les informations provenant de l'extérieur sur MySQL. On procède ensuite au redémarrage de notre service MySQL pour qu'il puisse prendre en compte la nouvelle configuration :
service mysql restart
Il nous faut maintenant créer un utilisateur qui sera utilisé par le serveur "Slave" pour venir récupérer les informations afin de procéder à la réplication en temps réel :
# On se connecte au serveur MySQL en ligne de commandemysql -u root -p# On créer l'utilisateur en questionCREATE USER "repuser"@"192.168.1.113" IDENTIFIED BY "passer" ;
IV. Configuration du master
Maintenant que notre environnement est prêt, nous pouvons passer à la configuration du serveur MySQL "Master". On commence donner les droits de réplication à notre utilisateur. Les droits "REPLICATIONS SLAVE" donnent le droit à l'utilisateur de recevoir les évènements de réplication sur son fichier binaire ("mysql-relay-bin") où le serveur "Master" écrit les modifications sur la ou les bases de données :


Nous allons regarder une première fois l'état de notre serveur MysQL "Master" en effectuant cette commande dans le terminal MySQL :

On a donc une information sur le nom du fichier "bin" dans lequel le serveur écrit les modifications sur les bases de données, la position de celui-ci et la ou les bases de données qui sont répliquées en temps réel. La quatrième colonne pourrais contenir les noms de bases de données à ne pas répliquer.
Notre serveur "Master" est maintenant prêt. Il ne faut plus que nous ayons d'écriture sur la base de données à présent car nous allons passer à la configuration du serveur "Slave". On bloque donc temporairement les écritures sur la base de données.
V. Configuration du slave
Nous allons maintenant passer à la configuration du serveur MySQL "Slave". Pour un rapide rappel, celui-ci va aller lire le fichier binaire du "Master" pour effectuer sur ces propres bases de données les mêmes modifications. On va donc dans un premier temps importer la base de données que nous souhaitons répliquer du "Master" vers le "Slave". Le but ici est que les deux serveurs démarrent avec la même version de la base de données :
# Sur le Master# On sauvegarder notre base de données dans un fichier 
# On envoie ce fichier sur le Slave

# Sur le Slave# On Création et importe la base de données dans notre service MySQL

Le "Master" et le "Slave" ont maintenant la même version de la base de données. Nous allons maintenant informer notre serveur "Slave" de l'existence du "Master" et lui dire d'aller lire les modifications à faire sur la base de données dans le fichier binaire reçu par le "Master". On va pour cela dans la configuration du service MySQL de notre "Slave" pour y ajouter ces lignes :

On redémarre ensuite notre serveur pour que les changements soient pris en compte :
service mysql restart
Nous allons maintenant nous connecter à notre serveur MySQL "Slave" pour lui renseigner le nom et la position du fichier binaire sur le serveur (ce sont les informations que l'on obtient en faisant un "SHOW MASTER STATUS;" sur le serveur "Master") :

# On redémarre notre status de slave
Nous allons ensuite voir les informations que nous avons sur notre "Slave" avec la commande suivante :
show slave status \G;
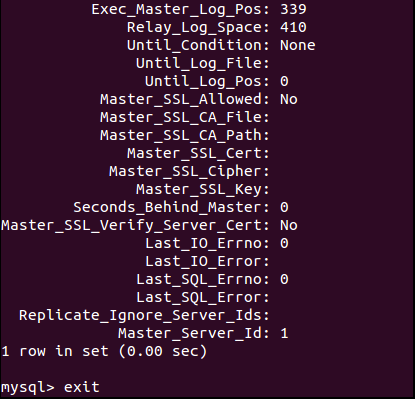
Nous voyons bien ici les informations de connexion du "Slave" vers le "Master". Pour être certain que la réplication s'effectue bien, les valeurs "Slave_IO_Running" et "Slave_SQL_Running" doivent être à "Yes". On remarque en première ligne également le "Slave_IO_State" qui est "en attente d'un événement du Master" ce qui indique bien que c'est au "Master" d'envoyer les événement de réplications et que pour l'instant aucun événement n'est en cours.
Notre "Slave" est maintenant bien synchronisé pour la réplication. Nous allons néanmoins faire un test basique pour nous en assurer.
VI. Test de la réplication en temps réel
réplication en temps réel de notre base de données. On ajoute une valeur à notre base de données du coté du "Master" :# Sur le Mastermysql -u root -p

On va ensuite directement vérifier du côté du "Slave" pour voir si la table « replication_table_ec2lt » a bien été répliquée :
# Sur le Slavemysql -u root -p

REPARTITION DE CHARGE AVEC HaProxy
Qu’est-ce que HaProxy?
Développée par le français Willy Tarreau en 2002, HAProxy est une solution libre, fiable et très performante de répartition de charge de niveau 4 (TCP) et 7 (HTTP).
Elle est particulièrement adaptée aux sites web fortement chargés qui nécessitent de la disponibilité.
Un serveur Haproxy a pour fonction première le Load-Balancing (répartition des charges) entre plusieurs serveurs web. Ainsi, en ne joignant qu’une seule IP (celle du serveur Haproxy) nous tomberont sur des serveurs web différents mais à contenu identique. Le but est donc de répartir les charges d’un seul serveur web sur deux ou plusieurs autres de façon transparente pour l’utilisateur.
Dans ce rapport, nous allons mettre en place trois serveurs
- Un serveur de répartition de charge avec HaProxy
- Deux serveurs web avec Apache et PHP
Voici la topologie que nous allons mettre en place:
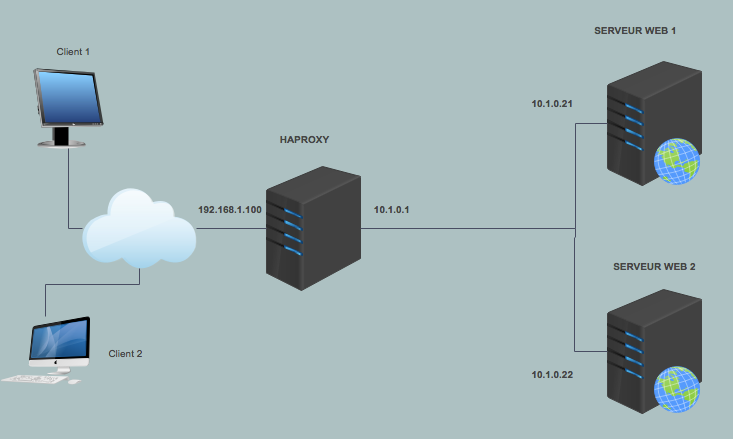
Une fois les cartes réseau de notre serveur de répartition de charge configurés correctement, nous allons pouvoir installer et configurer HaProxy.
Config IP du serveur
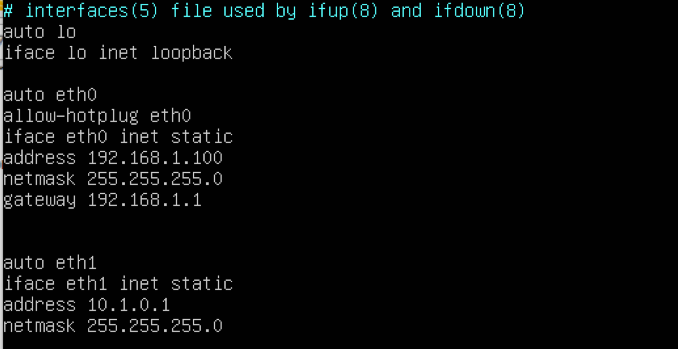
Malheureusement, HaProxy n’est pas dans les dépôts principaux de Debian, nous allons devoir utiliser les dépôts Backports pour l’installer.
echo "deb http://ftp.debian.org/debian/ wheezy-backports main" >> /etc/apt/sources.list
apt-get update
apt-get install haproxy
Une fois l’installation terminée, nous devons éditer la valeur ENABLED=0 à ENABLED=1 dans les fichiers /etc/default/haproxy et /etc/init.d/haproxy.
Vous pouvez le faire avec les commandes suivantes:

La configuration de HaProxy est assez simple et se fait dans un seul fichier de configuration, ce fichier se trouve dans /etc/haproxy/haproxy.cfg.

Analysons le fichier de configuration
listen cluster_web 192.168.1.100:80: Cette directive nous permet de spécifier sur quelle adresse IP HaProxy va fonctionner, nous allons accéder au contenu web depuis cette adresse IP.
mode http: permet de spécifier que le balancement de charge est utilisé pour du contenu web http, dans le cas contraire on peut utiliser le mode tcp (pour du myql par exemple ;) )
balance roundrobin: permet de spécifier l’algorithme de répartitionde charge. Il en existe plusieurs
- RoundRobin: La méthode Round-robin est une répartition équitable de la charge entre les serveurs d’un cluster. Chaque serveur traite le même nombre de requêtes, mais cela nécessite d’avoir des serveurs homogènes en termes de capacité de traitement.
- Source: Le mode de balancement « source » signifie qu’un client en fonction de son adresse IP sera toujours dirigé vers le même serveur web. Cette option est nécessaire lorsque les sites Internet utilisent des sessions PHP.
- Least connection: Le serveur renvoie vers le serveur le moins chargé. Si en théorie il semble le plus adapté, en réalité dans le cadre du Web dynamique, un serveur peut être considéré comme chargé alors que les processus sont en attente d’une requête vers une base de données.
- First Response: Les requêtes clients sont envoyées simultanément à tous les serveurs et le premier qui répond sera chargé de la connexion. Difficile à mettre en oeuvre et rarement employé.
server web1 10.1.0.21:80 check: permet déclarer les différents serveurs web qui vont êtres utilisé pour la répartitiont de charge
Enfin stats, permet de configurer la page de statistiques de HaProxy, dans cette configuration,la page de statistiques sera disponibles via l’adresse suivante http://192.168.1.100/stats avec les identifiants admin/admin.
Démarrez Haproxy avec la commande suivante:

Vous pouvez maintenant accéder à l’interface de statistiques de HaProxy via ’l’adresse:
http://192.168.1.100/stats
Vous pouvez voir sur l’image suivante que le serveur Web 1 est UP tandis que le serveur web 2 est DOWN.

Avant de mettre en place les serveurs Web, nous allons mettre en place l’IP forwarding sur le serveur LB pour que les serveurs Web aient accès à internet et aussi quelques rêgles iptables por mettre en place du NAT afin de pouvoir accéder aux serveurs Web via SSH.
Créer un fichier firewall dans /etc/init.d/ et copiez ceci dedans.
#!/bin/bash
##kachallah Abagana Mahamat
##kachou92.over-blog.com
start() {
echo -n "Application des regles IpTables: "
#Suppresion des anciennes rêgles
iptables -F
iptables -X
iptables -t nat -F
#Activation de l'IP Forwardings
echo 1 > /proc/sys/net/ipv4/ip_forward
iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE
##NAT pour SSH sur les Web
#Web
iptables -t nat -A PREROUTING -p tcp -d 192.168.1.100 --dport 2221 -j DNAT --to-destination 10.1.0.21:22
iptables -t nat -A PREROUTING -p tcp -d 192.168.1.100 --dport 2222 -j DNAT --to-destination 10.1.0.22:22
echo " [terminé]"
echo
}
stop() {
echo -n "Flush des regles IpTables: "
iptables -F
iptables -X
iptables -t nat -F
echo " [termine]"
echo
}
case $1 in
start)
start
;;
stop)
stop
;;
restart)
stop
start
;;
status)
/sbin/iptables -L
/sbin/iptables -t nat -L
;;
*)
echo "Usage: firewall {start|stop|restart|status}"
esac
exit
Enregistrez le fichier et faites les commandes suivantes afin de rendre le fichier exécutable et de pouvoir le lancer au démarrage:
chmod +x /etc/init.d/firewall
update-rc.d firewall defaults
Puis mettez en place les règles
Configuration des serveurs web. Maintenant que le serveur est configuré, nous allons pouvoir commencer à configurer les serveurs Web. En ce qui concerne les adresses des deux serveurs Web, n’oubliez pas d’utiliser comme passerelle l’IP du serveur haproxy. Voici la configuration IP de web1: 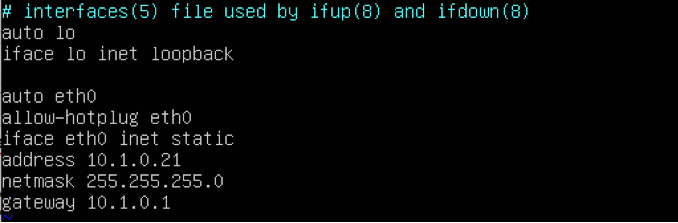 Voici la configuration IP de web2: 
|
Si web1 et web2 sont bien configurée, vous pouvez maintenant accéder à ces serveurs via SSH
- ssh root@192.168.2.100 -p 2221 pour web1
- ssh root@192.168.2.100 -p 2222 pour web2

Une fois sur ces deux serveurs, vous pouvez installer apache et PHP avec la commande suivante:
apt-get install apache2 php5
Une fois l’installation de apache et PHP terminée sur les deux serveurs, accédez à http://192.168.1.100/stats et vous verrez maintenant que tout est vert. Cela veut dire que HaProxy fonctionne maintenant.
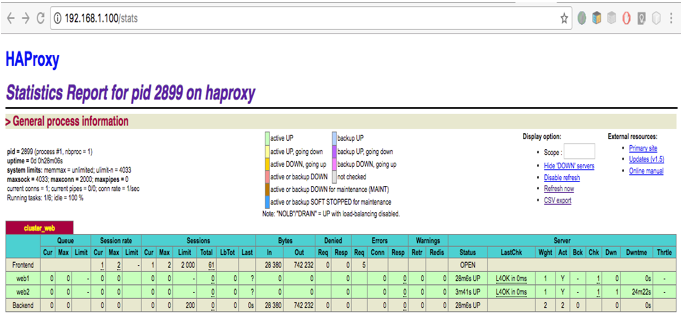
Vous pouvez accéder maintenant à http://192.168.1.100 et vous verrez la page par défaut d’Apache, mais vous ne savez pas sur quel serveur Web vous êtes.

Pour tester que la répartition de charge fonctionne, nous allons créer une page en PHP sur les deux serveurs web, cette page affichera le hostname de la machine.
Donc sur les deux serveurs Web, créez un fichier index.php dans le dossier /var/www/html et copiez ceci dedans:

Supprimez aussi le fichier index.html présent dans ce dossier.
|
Maintenant accédez à http://192.168.1.100 et vous verrez ceci:
Actualisons à nouveau la page


Cela veut dire que la répartition de charge entre les deux serveurs fonctionne
Ce qui est intéressant avec HaProxy, est le fait que si apache est stoppé sur l’un des deux serveurs, HaProxy va arrêter d’utiliser ce serveur.
Si par exemple vous arrêtez Apache sur web2, vous verrez sur la page de stats que web2 est marqué comme DOWN, si vous rafraîchissez la page http://192.168.1.100 seul web1 répondra, HaProxy a décidé de lui même de ne plus utiliser Web2.

Résultat sur http://192.168.1.100/stats

Résultat sur http://192.168.1.100

On remarque que même en actualisant n fois c’est toujours le serveur web 1 qui répond, c’est parce que Haproxy détecte que apache2 est stoppé sur serveur web 2 donc il décide de ne pas utiliser le serveur web 2 puisqu’il est DOWN.